引入在Databricks的过去几年中,我们看到了一种新的数据管理范式,该范式出现在许多客户和案例中:LakeHouse。在这篇文章中,我们将描述这种新范式及其相对于先前方案的优势。数据仓库技术自1980诞生以来一直在发展,其在决策支持和商业智能应用方面拥有悠久的历史,而MPP体系结构使得系统能够处理更大数据量。但是,虽 w397090770 5年前 (2020-02-03) 3002℃ 0评论6喜欢
下面论文均为大数据和分布式比较经典的论文,包括:CAP、BASE、2PC、一致性协议、一致性哈希、逻辑时钟、Leases 等。如果大家还有比较好的论文,欢迎在下面评论。分布式理论 Time, Clocks, and the Ordering of Events in a Distributed System Reaching Agreement in the Presence of Faults The Byzantine General Problem (CAP) Brewer's Conjecture and the Feasibility of w397090770 8年前 (2017-02-15) 3677℃ 0评论10喜欢
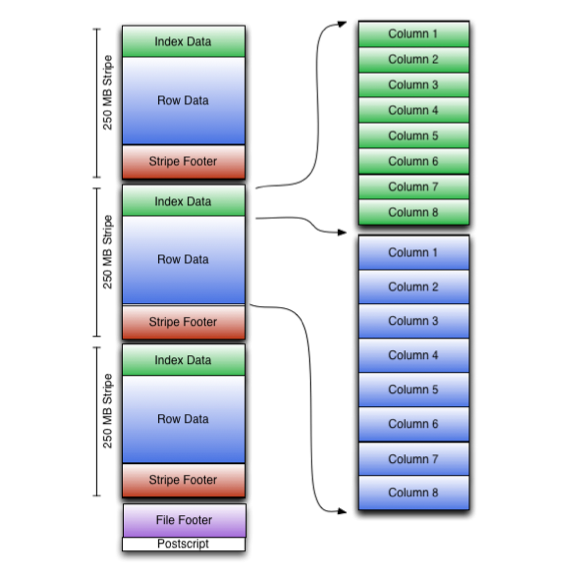
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 在Hive中,我们应该都听过RCFile这种格 w397090770 11年前 (2014-04-16) 83924℃ 9评论76喜欢
本文将介绍如何通过Flink读取Kafka中Topic的数据。 和Spark一样,Flink内置提供了读/写Kafka Topic的Kafka连接器(Kafka Connectors)。Flink Kafka Consumer和Flink的Checkpint机制进行了整合,以此提供了exactly-once处理语义。为了实现这个语义,Flink不仅仅依赖于追踪Kafka的消费者group偏移量,而且将这些偏移量存储在其内部用于追踪。 和Sp w397090770 9年前 (2016-05-03) 23935℃ 1评论23喜欢
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据。我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等。但是这些方式不是慢就是在导入的过程的占用Region资源导致效率低下,所以很不适合一次性导入大量数据。本文将针对这个问题介绍如何通过Hbase的BulkLoad方法来快速将海量数据导入到Hbas w397090770 8年前 (2016-11-28) 17774℃ 2评论52喜欢
本博客的《如何申请免费好用的HTTPS证书Let's Encrypt》和《在Nginx中使用Let's Encrypt免费证书配置HTTPS》文章分别介绍了如何申请Let's Encrypt的HTTPS证书和如何在nginx里面配置Let's Encrypt的HTTPS证书。但是Let's Encrypt HTTPS证书的有效期只有90天:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop到期之 w397090770 8年前 (2016-08-07) 1588℃ 0评论4喜欢
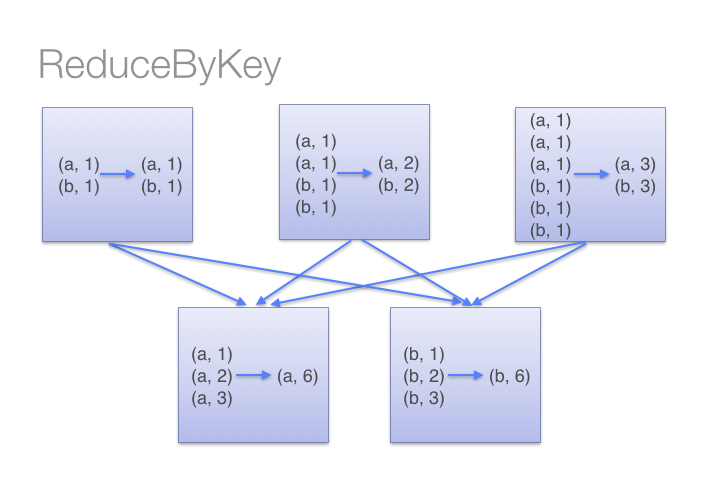
为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用 reduceByKey ;另外一种方式使用groupByKey,代码如下:[code lang="scala"]# User: 过往记忆# Date: 2015-05-18# Time: 下午22:26# bolg: # 本文地址:/archives/1357# 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 9年前 (2015-05-18) 33468℃ 0评论51喜欢
Elasticsearch 6.3 于前天正式发布,其中带来了很多新特性,详情请参见:https://www.elastic.co/blog/elasticsearch-6-3-0-released。这个版本最大的亮点莫过于内置支持 SQL 模块!我在早些时间就说过 Elasticsearch 将会内置支持 SQL,参见:ElasticSearch内置也将支持SQL特性。我们可以像操作 MySQL一样使用 Elasticsearch,这样我们就可以减少 DSL 的学习成本, w397090770 6年前 (2018-06-15) 8949℃ 3评论14喜欢
本文将介绍如何在 Kafka 中使用 Avro 来序列化消息,并提供完整的 Producter 代码共大家使用。AvroAvro 是一个数据序列化的系统,它可以将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。因为本文并不是专门介绍 Avro 的文章,如需要更加详细地 zz~~ 7年前 (2017-09-22) 7136℃ 2评论23喜欢
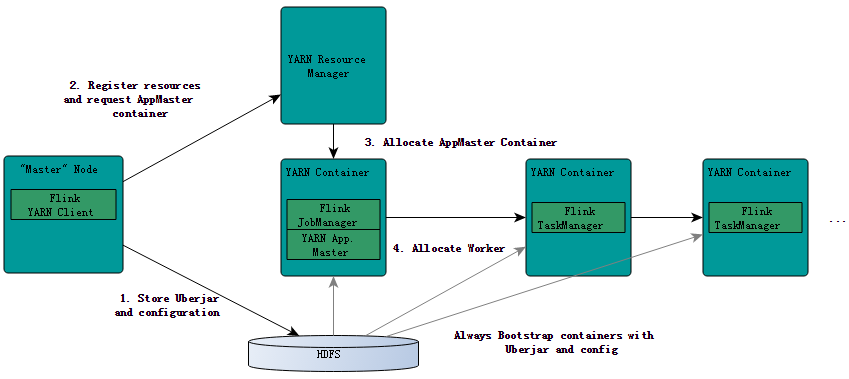
在前面(《Flink on YARN部署快速入门指南》的文章中我们简单地介绍了如何在YARN上提交和运行Flink作业,本文将简要地介绍Flink是如何与YARN进行交互的。 YRAN客户端需要访问Hadoop的相关配置文件,从而可以连接YARN资源管理器和HDFS。它使用下面的规则来决定Hadoop配置: 1、判断YARN_CONF_DIR,HADOOP_CONF_DIR或HADOOP_CONF_PATH等环境 w397090770 9年前 (2016-04-04) 6019℃ 0评论8喜欢
我们知道,Flume可以和许多的系统进行整合,包括了Hadoop、Spark、Kafka、Hbase等等;当然,强悍的Flume也是可以和Mysql进行整合,将分析好的日志存储到Mysql(当然,你也可以存放到pg、oracle等等关系型数据库)。 不过我这里想多说一些:Flume是分布式收集日志的系统;既然都分布式了,数据量应该很大,为什么你要将Flume分 w397090770 10年前 (2014-09-04) 25722℃ 21评论40喜欢
在本博客的《Spark 0.9.1源码编译》和《Spark源码编译遇到的问题解决》两篇文章中,分别讲解了如何编译Spark源码以及在编译源码过程中遇到的一些问题及其解决方法。今天来说说如何部署分布式的Spark集群,在本篇文章中,我主要是介绍如何部署Standalone模式。 一、修改配置文件 1、将$SPARK_HOME/conf/spark-env.sh.template文件 w397090770 11年前 (2014-04-21) 9479℃ 1评论5喜欢
在Flink中我们可以很容易的使用内置的API来读取HDFS上的压缩文件,内置支持的压缩格式包括.deflate,.gz, .gzip,.bz2以及.xz等。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是如果我们想使用Flink内置sink API将数据以压缩的格式写入到HDFS上,好像并没有找到有API直接支持(如果不是这样的, w397090770 8年前 (2017-03-02) 10295℃ 0评论6喜欢
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala w397090770 3年前 (2021-10-13) 811℃ 0评论3喜欢
将于2016年6月5日星期天下午1:30在杭州市西湖区教工路88号立元大厦3楼沃创空间沃创咖啡进行,本次场地由挖财公司提供。分享主题1. 陈超, 七牛:《Spark 2.0介绍》(13:30 ~ 14:10)2. 雷宗雄, 花名念钧:《spark mllib大数据实践和优化》(14:10 ~ 14:50)3. 陈亮,华为:《Spark+CarbonData(New File Format For Faster Data Analysis)》(15:10 ~ 15:50)4 w397090770 8年前 (2016-06-06) 2290℃ 0评论2喜欢
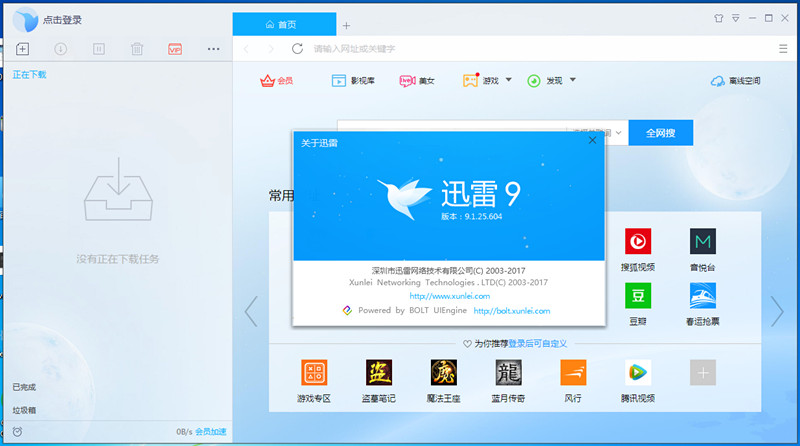
最近升级了迅雷9,新版本精简了任务列表的面积,然而增加了一个硕大的内置浏览器面板,大概占据了四分之三的窗口面积,并且不能关闭!界面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop就个人观点而言,实在不能理解为什么需要让一个下载工具的附加功能占据主要使用区 w397090770 8年前 (2017-02-18) 6421℃ 0评论20喜欢
我在《使用Hive读取ElasticSearch中的数据》文章中介绍了如何使用Hive读取ElasticSearch中的数据,本文将接着上文继续介绍如何使用Hive将数据写入到ElasticSearch中。在使用前同样需要加入 elasticsearch-hadoop-2.3.4.jar 依赖,具体请参见前文介绍。我们先在Hive里面建个名为iteblog的表,如下:[code lang="sql"]CREATE EXTERNAL TABLE iteblog ( id b w397090770 8年前 (2016-11-07) 19951℃ 1评论24喜欢
消息队列 消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环 w397090770 9年前 (2015-08-11) 8104℃ 2评论17喜欢
每次当你在Yarn上以Cluster模式提交Spark应用程序的时候,通过日志我们总可以看到下面的信息:[code lang="java"]21 Oct 2014 14:23:22,006 INFO [main] (org.apache.spark.Logging$class.logInfo:59) - Uploading file:/home/spark-1.1.0-bin-2.2.0/lib/spark-assembly-1.1.0-hadoop2.2.0.jar to hdfs://my/user/iteblog/...../spark-assembly-1.1.0-hadoop2.2.0.jar21 Oct 2014 14:23:23,465 INFO [main] (org.ap w397090770 10年前 (2014-11-10) 10900℃ 2评论12喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 5年前 (2019-06-06) 3258℃ 0评论8喜欢
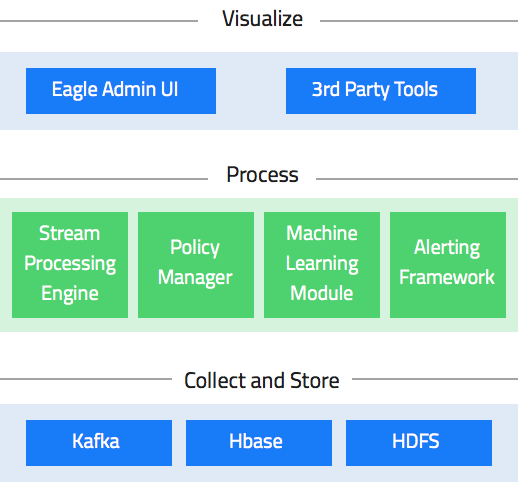
Apache Eagle 是由 eBay 公司开源的一个识别大数据平台上的安全和性能问题的开源解决方案。该项目于2017年1月10日正式成为 Apache 顶级项目。 Apache Eagle 提供一套高效分布式的流式策略引擎,具有高实时、可伸缩、易扩展、交互友好等特点,同时集成机器学习对用户行为建立Profile以实现实时智能实时地保护 Hadoop 生态系统中大数据的安 w397090770 7年前 (2018-01-07) 3179℃ 0评论8喜欢
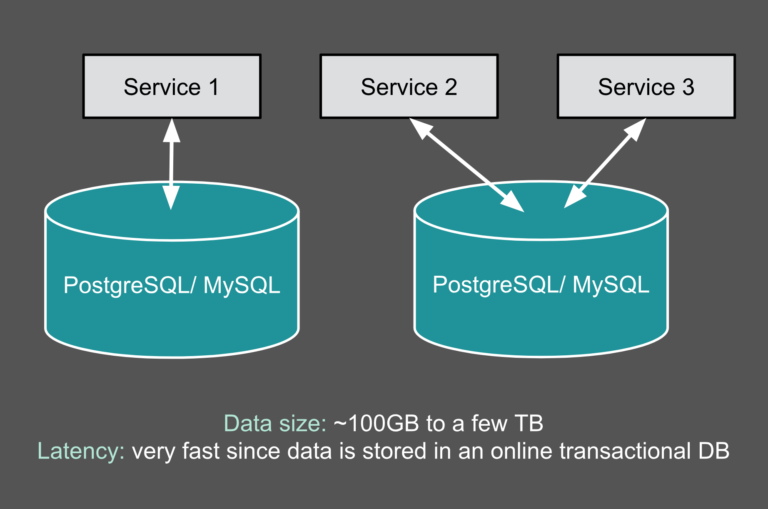
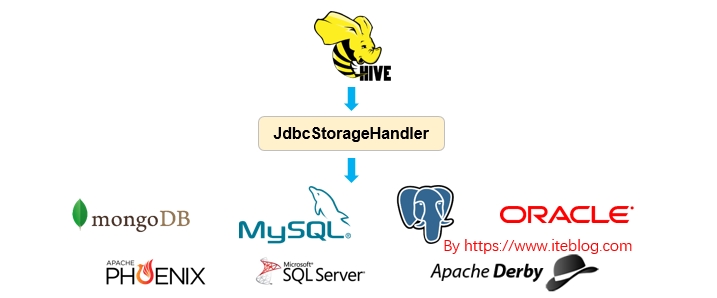
如今,很多公司可能会在内部使用多种数据存储和处理系统。这些不同的系统解决了对应的使用案例。除了传统的 RDBMS (比如 Oracle DB,Teradata或PostgreSQL) 之外,我们还会使用 Apache Kafka 来获取流和事件数据。使用 Apache Druid 处理实时系列数据(real-time series data),使用 Apache Phoenix 进行快速索引查找。 此外,我们还可能使用云存储 w397090770 6年前 (2019-03-16) 5146℃ 1评论8喜欢
Apache_Kafka于2013年10月出版,全书共88页。 w397090770 9年前 (2015-08-25) 3762℃ 0评论6喜欢
导语:此套面试题来自于各大厂的真实面试题及常问的知识点。如果能理解吃透这些问题,你的大数据能力将会大大提升,进入大厂指日可待。如果公司急招人,你回答出来面试官70%,甚至50%的问题他都会要你,如果这个公司不是真正缺人,或者只是作人才储备,那么你回答很好,他也可能不要你,只是因为没有眼缘;所以面 zz~~ 3年前 (2021-09-24) 2303℃ 0评论9喜欢
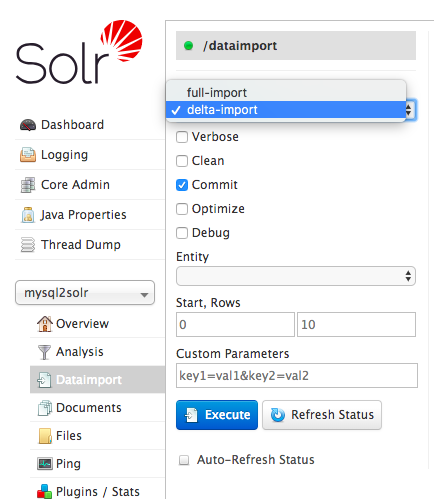
在 这篇 和 这篇 文章中我分别介绍了如何将 MySQL 的全量数据导入到 Apache Solr 中以及如何分页导入等,本篇文章将继续介绍如何将 MySQL 的增量数据导入到 Solr 中。增量导数接口为 deltaimport,对应的页面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop如果我们使用 《将 MySQL 的全量 w397090770 6年前 (2018-08-18) 1625℃ 0评论3喜欢
如果你经常写MapReduce作业,你肯定看到过以下的异常信息:[code lang="bash"]Application application_1409135750325_48141 failed 2 times due to AM Container forappattempt_1409135750325_48141_000002 exited with exitCode: 143 due to: Container[pid=4733,containerID=container_1409135750325_48141_02_000001] is running beyond physical memory limits.Current usage: 2.0 GB of 2 GB physical memory used; 6.0 GB of w397090770 8年前 (2016-12-29) 4191℃ 1评论11喜欢
将于2016年6月5日星期天下午1:30在杭州市西湖区教工路88号立元大厦3楼沃创空间沃创咖啡进行,本次场地由挖财公司提供。分享主题1. 陈超, 七牛:《Spark 2.0介绍》(13:30 ~ 14:10)2. 雷宗雄, 花名念钧:《spark mllib大数据实践和优化》(14:10 ~ 14:50)3. 陈亮,华为:《Spark+CarbonData(New File Format For Faster Data Analysis)》(15:10 ~ 15:50)4 w397090770 8年前 (2016-05-13) 2085℃ 0评论3喜欢
导言本文主要介绍如何快速的通过Spark访问 Iceberg table。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark通过DataSource和DataFrame API访问Iceberg table,或者进行Catalog相关的操作。由于Spark Data Source V2 API还在持续的演进和修改中,所以Iceberg在不同的Spark版本中的使用方式有所不同。版本对比 w397090770 4年前 (2020-06-10) 9992℃ 0评论4喜欢
一、百度(武汉地区)第一部分:1、描述数据库的简单操作。2、描述TCP\IP四层模型,并简述之。3、描述MVC的内容。第二部分:1、给出a-z0-9,在其中选择三个字符组成一个密码,输出全部的情况,程序实现。2、字符串的反转,比如abcde,输出edcba.3、许多程序会大量使用字符串。对于不同的字符串,我们希望能够 w397090770 12年前 (2013-04-15) 13371℃ 0评论9喜欢
Google的Chrome浏览器很不错,很多人都希望能在CentOS里面用上chrome,于是用下面的命令来安装Chrome:[code lang="JAVA"]yum install google-chrome-stable[/code]但是一般都会出现以下的情况:[code lang="JAVA"]Error: Package: google-chrome-stable-28.0.1500.95-213514.x86_64 (google64) Requires: libstdc++.so.6(GLIBCXX_3.4.15)(64bit) You could try using --skip-broken to work w397090770 11年前 (2013-10-24) 6808℃ 1评论6喜欢


![通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]](https://www.iteblog.com/pic/hbase_Bulkload_iteblog.png)